With the advances in data science and the availability of more efficient methods of data extraction and wrangling, there has been an interest in extracting metadata from the vast amount of data available in many areas of science and technology. I have also been involved in two such efforts.
I was part of a team that performed a metadata analysis on neurotransmitter responses to clinically approved and experimental drugs. We extracted metadata from more than 1400 different published studies. In each study, the effect of a given drug on neurotransmitter concentration in a certain brain region has been measured. We used data science and machine learning tools to check whether the official categorisation of the drug matches how it actually affects the brain. In other words, if two drugs are categorised as anti-psychotic, do they affect different neurotransmitters in different brain regions similarly? I don't think it comes as a surprise to anybody that what we found for many drugs it is not the case. The full report is published in Nature Communications.
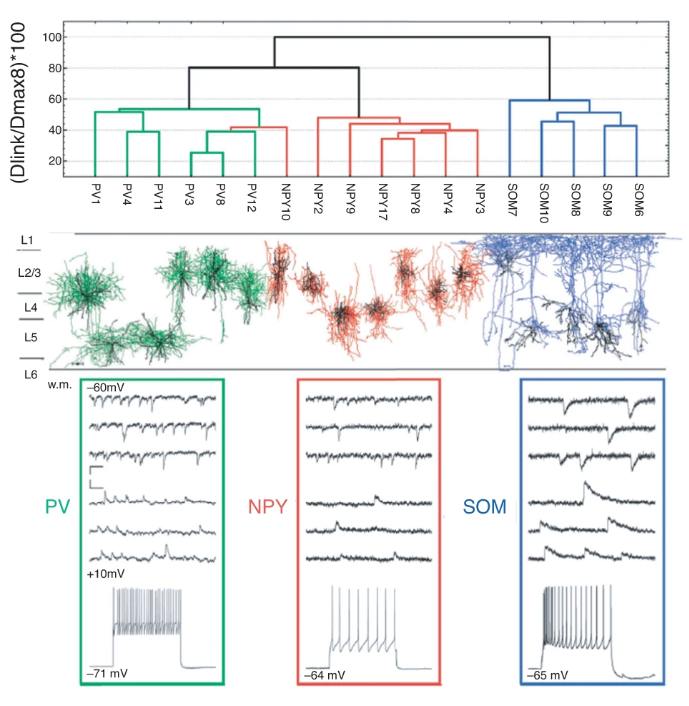
The other metadata analysis is a very ambitious project. I was part of a group of neuroscientists from all over the world, whose aim is to classify cell types in the nervous system. It is just the first step and there is a long way to go, but it is a step in the right direction. The full report was published in Nature Neuroscience journal.